



Unleashing the Power of Vector Databases and Embeddings: Beyond Relational Data
In the realm of data-driven decision-making, our ability to process and analyze vast amounts of information is paramount. Traditional relational databases have been our trusted companions for decades, serving as the backbone of data storage and retrieval. However, vector databases - utilizing embeddings - can revolutionize how we handle data, offering richer insights and more nuanced comparisons.
The traditional relational database
Let's start with the basics. Traditional relational databases are like well-organized spreadsheets. They excel at managing structured data, where information is neatly organized into rows and columns. For instance, think of a database that stores information about football players, with rows representing players and columns for attributes like name, age, and speed.
In such databases, data is primarily one-dimensional. You can easily sort or filter players based on a single criterion, like speed. It's akin to lining up players on a single line, from the fastest to the slowest. Simple and straightforward, right?

The limitations of one-dimensional thinking
But here's the catch: in real life, players possess a myriad of attributes, not just speed. They have strengths and weaknesses in areas like weight, agility, and skill. Traditional databases struggle to capture this multi-dimensional complexity. It's like trying to describe a player's skills with just one number - limiting and inadequate.
Vector databases and embeddings
This is where vector databases and embeddings swoop in to save the day. They introduce a whole new dimension (pun intended) to our data analysis toolkit. Instead of squeezing everything into a single dimension, we embrace multi-dimensional thinking.
Imagine each player as a unique point in a multi-dimensional space, like a graph with multiple axes. One axis represents speed (X), another weight (Y), and so on. Players are no longer confined to a single line; they scatter across this multi-dimensional landscape.
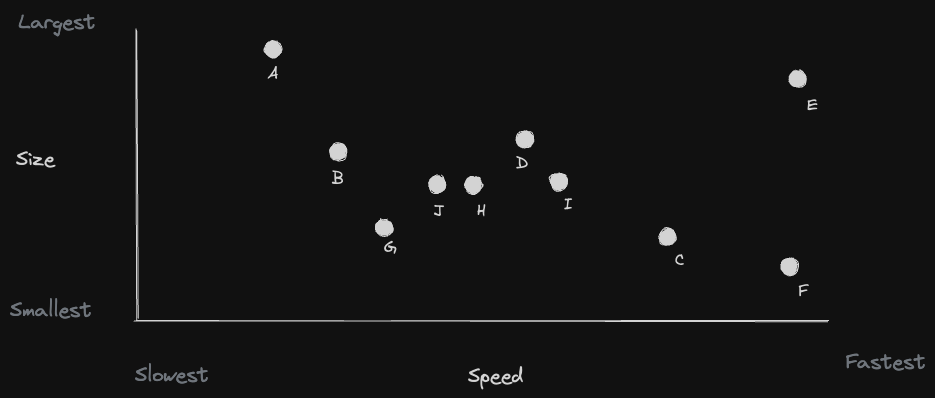
The power of multi-dimensional thinking
Here's where it gets exciting. In this rich data space, we can now assess player similarity based on multiple criteria. Want to find players who are not only fast but also have similar weights? No problem. Looking for players with exceptional agility and skills? You got it. The possibilities are endless.
However, this isn't only limited to two dimensions. The more complex these models become, the more dimensions they allow us to represent.
Vector databases and embeddings let us explore and compare data in ways that traditional databases could only dream of. They provide a more comprehensive and nuanced understanding of our data, unlocking insights that were previously hidden.
Beyond football: real-world applications
While our football analogy helps grasp the concept, the real-world applications of vector databases and embeddings are immense. Think recommendation systems, where they can identify products or content similar to your preferences based on various attributes. In healthcare, they can assist in diagnosing diseases by considering a patient's diverse medical data.
Embracing the multi-dimensional future
In our data-driven world, embracing multi-dimensional thinking is the key to staying ahead. Vector databases and embeddings offer a fresh perspective on how we handle data. They break free from the confines of one-dimensional databases, allowing us to explore, compare, and analyze information in ways that were once unimaginable.
So, the next time you encounter a complex dataset, remember that it's not just about one attribute; it's about a rich tapestry of information waiting to be untangled. Embrace the multi-dimensional future, and you'll unlock a world of insights that will shape the way you see and understand data.
In the ever-evolving landscape of data science, vector databases and embeddings are the torchbearers of progress, lighting the path to a more profound understanding of our data and, ultimately, a smarter, more informed world.